Spot-friendly CI pipeline: Persistence

This is part two of a three-part series where we deep-dive into how Rippling moved to AWS Spot Instances for CI. In this post, we'll cover some of the implementation challenges.
There are huge cost benefits for switching your CI worker EC2 instances to use AWS Spot Instances, but there are also challenges (read my teammate Remy’s previous post to learn more). At Rippling, our main repository has over six million lines of Python code and over 55,000 tests (with close to 700 engineers expanding the size of this repository on a daily basis)—so these savings translate to millions of dollars annually.
When we implemented this change at Rippling, the most important challenge was managing the persistence of work in the event of a spot interruption. Typically, when using on-demand or reserved instances, you can safely assume that the instances assigned to particular tasks will remain operational and not be deleted before their tasks are finished. This stability allows simple architectures with minimal failure recovery, like the example below (e.g. lint code and build artifact → test in parallel → collect results), to suffice for day-to-day operations.
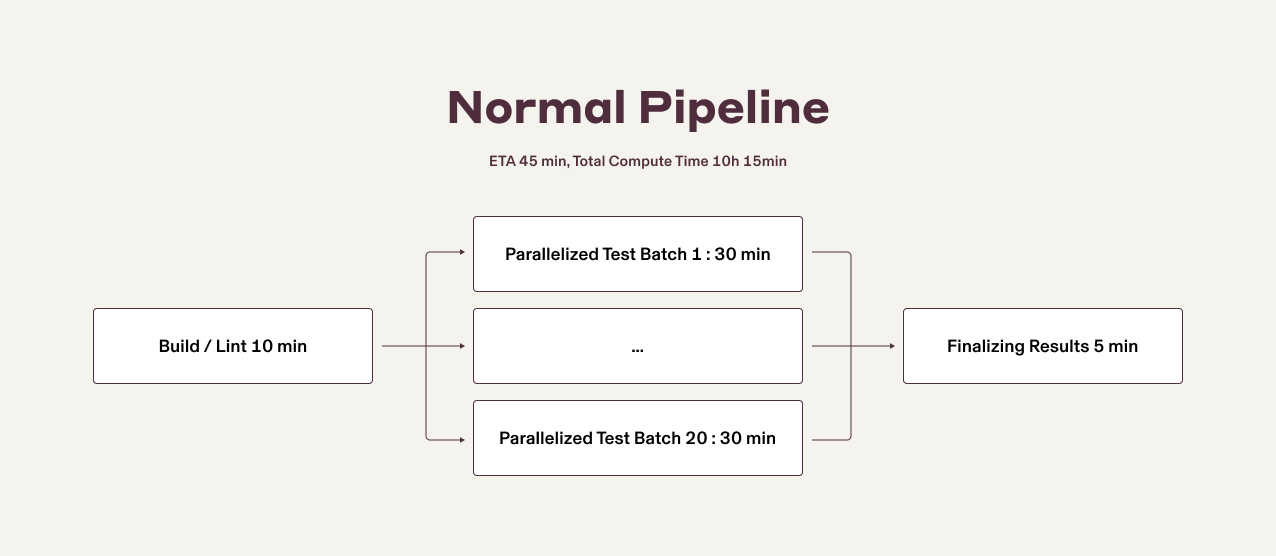
When using spot instances, however, we can’t make the same assumptions: as clearly explained in the spot instance documentation, your spot instances can be interrupted or killed at any moment (after a two-minute notice). This means that the previous architecture, as is, suffered long and unexpected retries as either fully blocking steps or entries in a “wait group” of steps like a test batch experiencing an interruption. Sure, these spot interruptions don’t happen every time, but they happen enough to noticeably impact both engineering CI experience and mean/p50 stats of the pipelines using them. We moved to spot, but then noticed that the spot interruption increased our median and average build times by ~33%—this was a deal-breaker that we had to fix asap.
One of the primary missions of the Developer Experience team at Rippling is to provide a better user experience, and the slowing of the build is not an acceptable trade-off. This degradation was a deal-breaker for using spot instances—unless we figured out a way around them.

How to retry
In order to adopt spot instances, it's essential to have a method to identify failed CI steps and retry them. I won’t go into detail here about this because there are many nuances between CI systems on how they manage retries. At Rippling, we use Buildkite's Step Retry configuration options. Specifically, we use the following:
1
2
3
4
5
6
7
retry: &retry
automatic:
- exit_status: -1 # CI Agent was lost (disconnected suddenly)
signal_reason: none
limit: 4 # Retry 4 times if step "failed" for this reason
- signal_reason: agent_stop # CI Agent was stopped (OS sent sigterm/kill)
limit: 4 # Retry 4 times if step "failed" for this reasonOther systems like Jenkins have plugins like EC2 fleet with official AWS posts on how to handle spot interruptions with it. Be sure to check the docs for your system.
Identifying the root problem
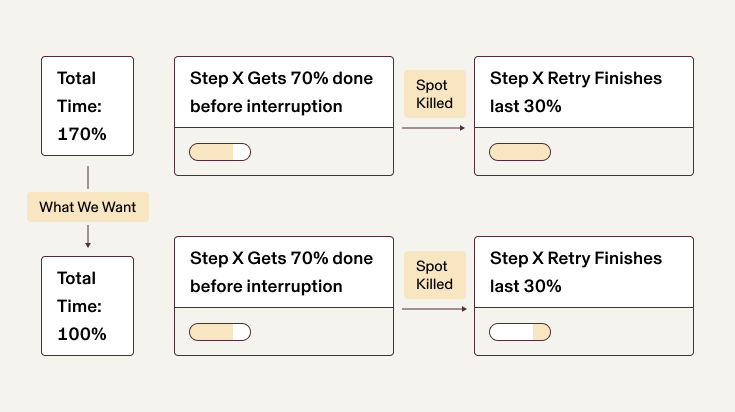
First, we took a step back to understand what we were trying to solve. We realized that the CI workflows were now taking longer, but we needed to get to the root of the problem. It just so happened that this was because of the spot retries, but neither we nor our CI pipeline time metrics cared about that. Following that train of thought, using spot takes longer because when a step is retried, it needs to redo all of its work. If a new step could pick up the work at the point where its predecessor was killed, then the added time would be limited to retry overhead (i.e. CI step setup/code checkout).
In the example below, we have a Step X which is now taking 170% of how long it would usually take because it was first interrupted when it was 70% complete and now has to redo 100% of the work. What we want is to only have it redo the remaining 30% of the work.
The checkpointing solution
In response, we came up with our checkpointing system. It was tailor-made to work with our pytest parallel testing steps because those are by far the longest running and most interrupt-prone sections of our pipelines, but its philosophy can be applied to most other testing suites and CI steps.
As mentioned in the previous section, the key to the problem is being able to preserve the progress from the interrupted step. To that end, we have created two options/fixtures which we’ve added to pytest in our root conftest.py: a “passlist” and a “skiplist.”
- Passlist: a passlist is a list global to a pytest session that keeps track of the names of all the tests that have passed as the test suite progresses and regularly flushes its contents to a given text file (inputted as pytest option).
- Skiplist: a skiplist is a text file (inputted as a pytest option) that is supposed to hold the names of all the tests that are to be skipped in the current test session.
As you might have guessed, the generation and preservation of these pass/skip lists is how the work progression is saved between runs:
- Prior to test start, we attempt to download any existing passlists from a previous run that we are retrying. If we find such a passlist, we input it as a skiplist to pytest.
- On pytest start, we pass the option to keep a passlist, “checkpointing” the work done so far.
- On the test step we set a pre-exit hook that, just prior to exiting, uploads the current passlist as-is to our artifact store.
- On retry due to spot interruption, we go back to step one and all previously passed tests are now skipped.
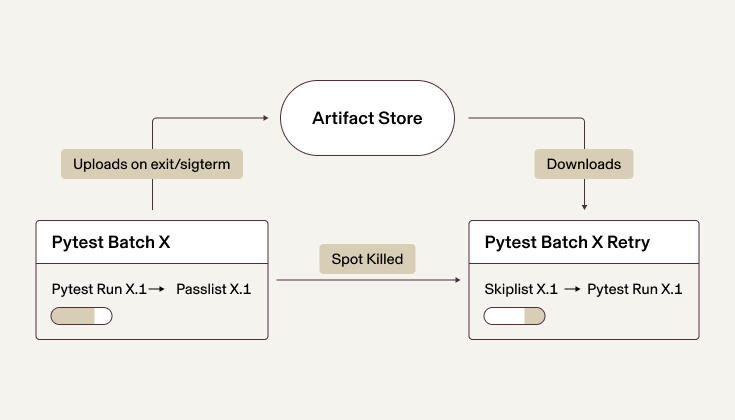
The pass/skiplist serves as the “checkpoint” for our work, making sure that tests that have already passed are never rerun. The lost time is now reduced to just the setup overhead (~3 minutes) and any failed tests (which is usually no more than ~10 out of +55K tests for most of our pull requests). For guidance, you can see this part of our code here!
Artifact storage and identification
We’re assuming that your team has access to some sort of remote storage to serve as your artifact store and a way to identify the artifacts from its previous tries. We’re comfortable with these assumptions because:
- If your CI system doesn’t offer an artifact store system, then a simple AWS S3 bucket would do the trick; and
- Most/all CI systems do a really good job of having unique IDs for each step and exposing them.
Some folks may also want to consider using block storage for persistence as opposed to a remote artifact store. This is a good idea if you have big artifacts and network latency and/or price is a concern. But it does pose new problems in ensuring that your replacement worker is in the same availability zone as its predecessor. Our artifacts were tiny (~1KB) and storage is cheap so we didn’t have to worry about that!
Solving the work persistence problem—and looking ahead

And that’s how we solved the work persistence problem with spot usage and were able to move forward with spot adoption in Rippling CI! By having the CI tests pick up where their predecessor died, we were able to mitigate most of the time lost due to spot interruptions. There was a lot of extra work to reduce the overhead and even identify the spot interruptions to retry–we were actually the team that pushed BK to add the ‘signal_reason’ retry field.
Still, after six months and much trial and error, this core architecture remains the foundation and it has worked well for us: our median and average build times dropped by ~25% and I can’t remember the last time our team needed to do a manual intervention, or an engineer complained about spot interruptions in their CI runs!
I’ve left hints around the article of other projects and enhancements at play, but even our saga of spot usage isn’t finished as we haven’t talked about the second biggest challenge: observability and response. Stay tuned as the Rippling team explores these subjects in upcoming posts.






