Recommendations at Rippling: Powering the Rippling Campaign Platform

Rippling’s journey into machine learning began with our campaign delivery platform, designed to inform Rippling users about our diverse offerings. This initiative posed a number of challenges, such as parsing a wealth of product offerings, managing a cold start problem from a new product, and balancing a wide variety of desired user interactions. Overcoming these challenges came with great rewards: After the initial launch of the recommendation engine, campaign clicks increased 2.5x compared to the previous manual ranking method.
In this article, we unpack the successful development of our machine learning recommendation engine. We’ll share key takeaways from feature engineering, detail our offline and online evaluation strategy, explain the ranking schema around our machine learning models, and discuss how we incorporated pacing.
About Rippling messaging campaigns
At Rippling, various teams need to engage with our users, be it to showcase new features of existing products or introduce the latest product launches. To facilitate these interactions, we’ve developed a ‘campaign’ platform. This platform enables everyone, from marketers to product managers, to craft their own campaigns.

An example banner about Rippling App Management
These campaigns are versatile, appearing in different formats such as modals, banners, coachmarks (interactive tooltips), and floating action buttons. They’re also displayed across the app, from the home dashboard and app store home page to the reports dashboard and the conclusion of the hiring process. This flexibility ensures we can engage Rippling users precisely where and when it’s most relevant.

An example banner about a useful workflow
When a campaign is set up, the creator defines its target audience, specifying which individuals and companies will see it. It’s not uncommon for audiences to overlap. In cases where a user qualifies for multiple campaigns simultaneously, we must prioritize which one to display.
Upon accessing a page, a user could be eligible for hundreds of different campaigns on that page alone. Deciding which campaign to display—or whether to show any—requires careful consideration of several factors: the campaign’s desired outcomes (such as clicks or sales), the need to balance these objectives over time across campaigns, and the potential intrusiveness of certain formats.
This decision-making is crucial for meeting business objectives and cultivating a meaningful user experience. Our campaign creation and delivery platform is responsible for making millions of these decisions daily. The impact is substantial—these campaigns drive a significant portion of Rippling products’ cross-sell and are a primary way to heighten engagement with underutilized features. With such a broad spectrum of campaigns, nailing relevance is essential.
Galaxy, our recommendation engine
We built Galaxy, a microservice that sits behind our API gateway, to power this decision-making. As our recommendation engine, Galaxy handles machine learning feature collection, model inference, and ranking score calculation using services like DynamoDB and Sagemaker. Beyond campaign ranking, Galaxy also powers our broader range of recommendation products.

Galaxy within the context of a single request for a campaign
Today, Galaxy linearly combines the output of several different models we have built to output a final ranking score for each campaign it has passed.

An overview of what happens in ranking within Galaxy
When we first launched Galaxy for campaign ranking, we observed a 2.5x improvement in campaign clicks compared to a manual product ranking list. Subsequent improvements—like adding model features, creating new models, and refining our ranking approach—further boosted click rates, minimized campaign dismissals, and drove notable increases in cross-sell sales. In the next section, we’ll dive into both our initial strategy and these pivotal enhancements.
Key considerations
Implementation strategy
We started with a much simpler model and ranking methodology than we have now. Establishing our inaugural machine learning use case involved key system integrations: setting up the microservice with our API gateway, integrating with Snowflake, and building observability with Datadog. On top of that, we needed to gather training data, create valuable features, and adapt existing modeling techniques to best meet our objectives.
We began with basic techniques, allowing us to transition smoothly from a manual prioritization to a machine-learning-driven process. We assessed offline performance using metrics such as AUC-ROC (Area Under the Receiver Operating Characteristic Curve) and F1 score to iterate on the model. We also simulated ranking choices to examine differences between what the model would choose and the prior manual methodology. We sanity-checked model score distributions and sampled ranking decisions given the system’s relative simplicity. These checks allowed us to quickly reason about and debug potentially erroneous ranking choices. Once we felt comfortable, we moved to an online A/B test—this allowed us to converge to an impactful first launch quickly.
Our initial focus was on two models: a click model, aimed at predicting users’ clicks on call-to-action buttons (CTAs), and a dismiss model, designed to predict when users would exit banner campaigns. This approach held an abundant amount of data, a fast feedback loop for incorporating shifts in a new and fast-growing platform, and compatibility with diverse campaign goals.
We started with a logistic regression model due to its solid foundational performance, ease of management, efficiency on our initial small dataset, and high interpretability. As we explored further after the initial launch, we transitioned to gradient-boosted decision trees, which exhibited better offline and online results.
We continued to take methodical steps throughout the process, using A/B testing to validate ranking changes. We established a standard set of tracking metrics and guardrails around clicks, dismisses, impressions, and content expands. Through this systematic method, we integrated new models and determined their initial weight in the linear combination based on observed metric tradeoffs.
Feature engineering
In refining our machine learning model, we extensively tested various features. Each model iteration underwent offline performance evaluations based on the addition or removal of features. The most promising iterations were benchmarked in an online experiment against our baseline model. Key features we incorporated include:
- Past interactions: user interactions with other campaigns, considering factors like the product involved, the time period rollup, the type of unit, and the nature of the interaction
- Campaign details: features related to the campaign, such as the product it represents, the format it’s configured to display as, and the objective of the campaign
- User attributes: details about the user viewing the unit, including their title at the company and their tenure
- Company attributes: details about the company, including its size and industry
In building these features, we faced several challenges:
- Data limitations: While past interactions with a specific ad were valuable indicators due to the limited campaign inventory we had, many users had limited interactions. Most users benefit from Rippling even without using the app itself frequently. To mitigate this, we broadened the scope of such features, examining past interactions with different dimensions of aggregation, like the underlying product.
- Title inconsistency: Our users' role titles aren't standardized across companies. A title in one company might signify a similar level of seniority or function as a completely different title in another company. To address this, we used personas—a heuristic-based categorization of roles. This reduced the cardinality of the categorical feature and enhanced the feature’s effectiveness.
- Cold start: In the early stages, interactions with campaigns were limited due to the new and growing nature of the campaign platform. As a workaround, we integrated interactions with other parts of the Rippling app, such as including a list of a company’s installed apps.
Additional adjustments
Occasionally, there’s a compelling business case to prioritize impressions of new products or special campaigns over other campaigns. To address this, we developed a process that temporarily boosts the scores of such campaigns using an impression-decaying multiplier on a specific model. This approach allows for rapid delivery to a large audience without long-term negative impacts, balancing both the model’s goals and the business’s needs.
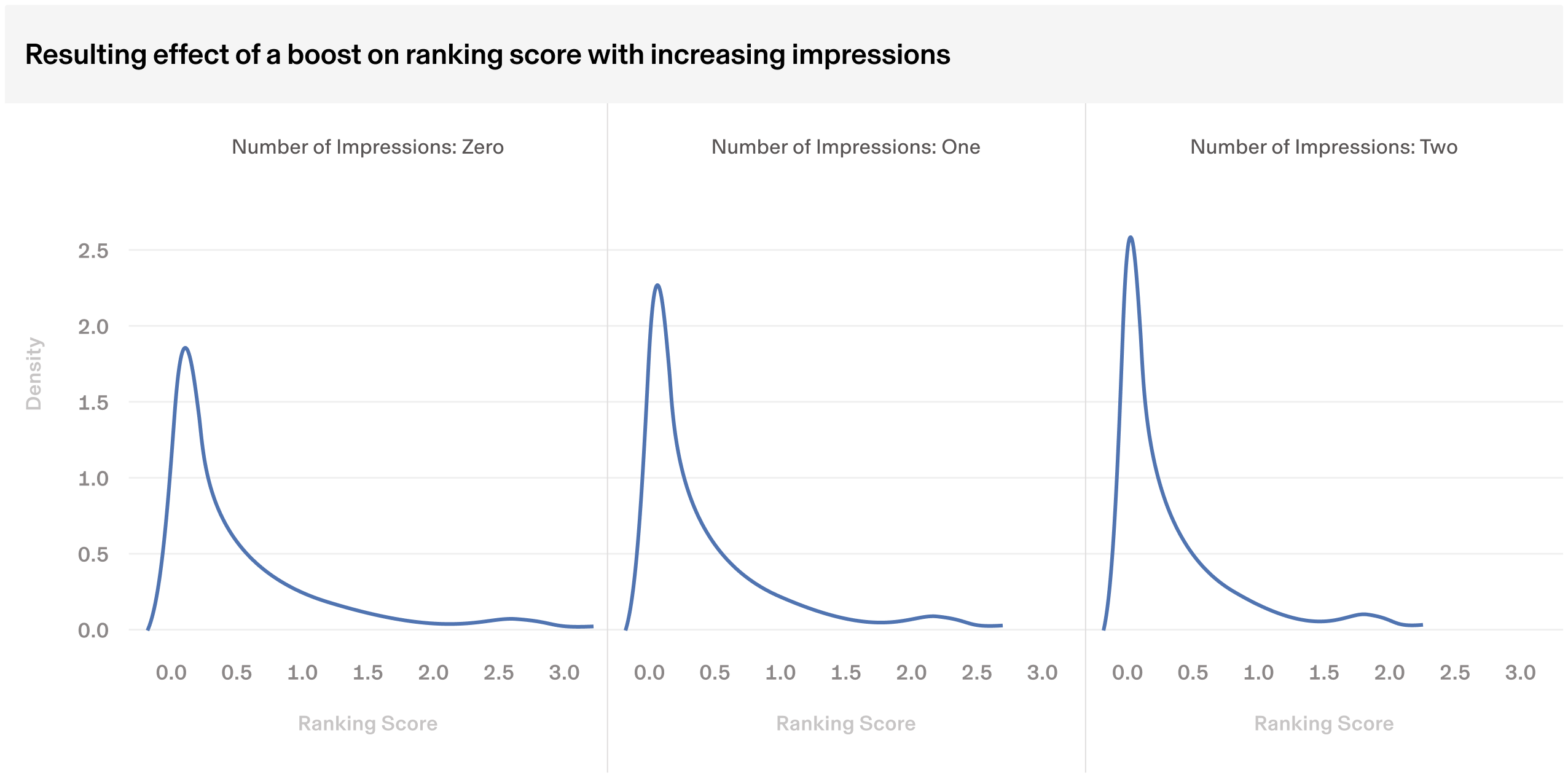
Resulting effect of a boost on ranking score with increasing impressions
Our machine learning feature pipelines rely on periodic background jobs, so features don’t always immediately reflect user feedback. Because of this, and to ensure a quality user experience beyond what our model captures, we apply score reductions based on the number of impressions within a certain timeframe. Although our model can adjust for this in the short term, we sometimes need to impose additional reductions to align with long-term user engagement goals not yet included in our modeling.
We’ve also added thresholding to our ranking process, addressing the earlier problem: “Should we show an ad at all?” Depending on the campaign objective and the ad’s format, we set a minimum value for the ad’s display. To determine the right parameters for these adjustments, we compare long-term metrics with different parameter sets and observe how short-term metrics, like impressions, are impacted. We were able to drive down impressions by 22% without affecting our long-term outcomes.
Pacing
For certain campaign types, like modals, we use extended intervals between displays compared to others, such as banners. This approach, especially when multiple teams roll out campaigns without synchronization, can sometimes lead to inefficiencies. This can even happen within campaigns managed by one owner. If we consistently show the top-ranking campaign today, a potentially better campaign tomorrow might be sidelined for an extended period since it missed its turn to be displayed.

Rough illustration of pacing’s impact on two overlapping campaigns: The ‘After’ scenario showcases improved exposure for Campaign B upon launch and allows for iterative refinement of Campaign A over time
To address this, we adopted a pacing mechanism in our ranking scheme. Pacing ensures that newly introduced campaigns are gradually exposed to their target audience over a short timeframe. This is achieved by constraining daily exposure relative to the total audience size and the pacing duration. With pacing, there are two key benefits for our campaign creators:
- Campaign owners receive quick feedback, allowing them to adjust the campaign before it reaches an even broader audience.
- Newly launched campaigns can compete fairly for impressions with other campaigns introduced shortly before them.
Building out machine learning infrastructure
From the ground up, we’ve built a robust machine learning infrastructure on top of Sagemaker. This infrastructure supports concurrent model iteration, multi-version experimentation, real-time inference, and recurring model training. We’ll introduce this infrastructure’s evolution and its current capabilities here, saving an in-depth exploration for a future article.
Initially, we adopted a batch processing system. Our choice was due to our iterative approach to building out this system, a comparatively smaller campaign inventory, and the then-stability of most feature values. Batch processing generated outputs for every user-campaign pair across all models at varying frequencies, balancing model performance against computational cost. We were able to yield significant online metric improvements with these models calculated offline, demonstrating a strong payoff of this batch processing approach.

Our existing model training pipeline
Fast forward to today: Our models employ real-time inference with up-to-date features. These models are supported by a continually evolving ML platform, which streamlines the creation of new models, refining existing ones, and testing experimental versions–all with minimal code required. Additionally, these models can be scheduled for recurring training with automatic monitoring of their offline performance. We also monitor model performance in production, capturing metrics for offline evaluation, score distributions, and inference latency.
Where to next
Machine learning at Rippling offers vast potential, with many applications and products yet to be built. Even within the realm of the campaign platform, there’s considerable depth to be explored. Our future endeavors include coordinating campaigns across other channels, such as email, and further refining our modeling approaches. Crafting a solution for the campaign platform was more than just assembling a few models; it necessitated building a foundational infrastructure, formulating precise processes, and designing robust modeling schemes to cater to the evolving demands of Rippling’s campaign platform. Stay tuned for future posts where we’ll delve into other recommendation products and share more about our machine learning infrastructure.










