Code ownership at Rippling

One of the biggest reliability challenges we faced at Rippling was scaling up routing for code errors. When a test failed or code broke in CI (or later in the deployment pipeline), it used to take a lot of time to identify which team to reach out to for a solution.
With over 700 engineers across dozens of teams working in a Python monorepo of millions of lines of code (along with several repositories in other programming languages), the slow, manual routing just wasn’t sustainable.
This growth blocker is why we built the Rippling Service Catalog, an internal tool that programmatically determines code ownership and outputs structured outreach data. Building the service catalog was an organization-wide effort that required buy-in from all the engineering teams to formalize their previously ad hoc communication channels. But thanks to this tool, we were able to switch almost all test failure incidents from ad hoc, manual investigations to an automated notification system. This was a game changer for the whole CI/CD workflow, positively impacting our ability to directly fix code errors, indirectly helping us scale infrastructure support, along with other far-reaching institutional changes, like budgeting resource management, engineer toil, and much more. Let’s dive in.
The concept of code ownership
Code ownership isn’t really a new problem, nor is it lacking in implementations, references, or resources. For example, GitHub has a code owners system built into every repo. Code ownership is a cornerstone of the case for service-oriented architecture (SOA). Even googling “code ownership” returns many pages of articles about different aspects of the concept.
Yet, many of these definitions have different implications; when GitHub says “code owners,” it functionally means, “Who can review changes for this code?” That’s different from the “How is this deployed?” definition provided by SOA code ownership, which is also different from the “Who works on this code?” definition from the Agile Alliance.
The bottom line: “Who owns a piece of code X?” can be interpreted in many ways, for different purposes, and at many levels in an organization.
For this article, we’ll consider code ownership from the perspective of reliability: Given a piece of code, we want to know who to contact or alert if it breaks in the CI/CD pipelines so that we can fix the issue confidently and quickly. As infrastructure engineers, this is our primary interpretation of code ownership. It also used to be one of our biggest headaches.
Consequences of unclear ownership
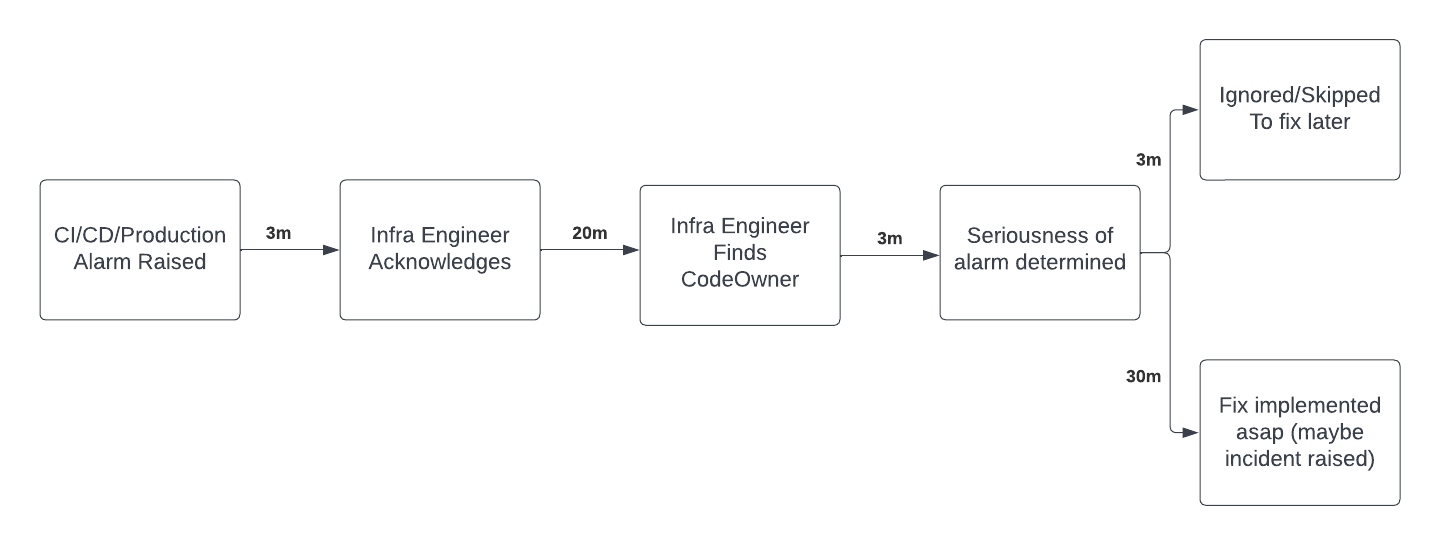
Infrastructure engineers have many important responsibilities, and one of the most important is deploying timely, tested code without disrupting production. Infrastructure organizations may be structured into different sub-teams, but most teams are built around this key responsibility. Across my diverse professional experiences, handling alarms for this responsibility (i.e., failures in CI/CD) usually manifested in an on-call system, where the on-call infrastructure engineer had to go through a process like the one diagrammed above to fix a reliability issue. This is a fairly common experience, and when I joined Rippling, it was no different.
By far, the most painful and bespoke leg of this workflow is when the on-call infrastructure engineer needs to find the code owner (as defined in the last section) from the error data gathered in the system. Oftentimes, there isn’t a solid process for this solution. I’ve seen teams rely on tribal knowledge, although some teams develop playbooks (with varying degrees of quality), which help a bit.
Sometimes, when an error occurs, the on-call infrastructure engineer knows the file personally and who to contact. Other times, git history shows a very recent change with the failed line, so the infrastructure engineer can see who’s responsible. But that’s not always the case. If the file has been unchanged for over a year, the best thing to do is call an “old guard” who knows all the old files in the company. Sadly, all of these inquiries will fail if that person is indisposed when you try to reach them (e.g., sleeping, in a meeting, away for the weekend, etc.).

Worst of all, the problems only continued to increase as the engineering department and codebase grew. Individual infrastructure engineers knew less and less of the codebase, decreasing the probability of quick fixes. More and more teams were created, which made finding the correct person more difficult. And more time was spent on support/maintenance, so less time could be devoted to making improvements. As error rates increased and took longer to fix, it became harder to scale the engineering team further.
To review, the consequences of not having clear code ownership included:
- Unreliable and slow incident responses
- Inability to automate incident responses
- Slow training for new infrastructure engineers
- On-call burnout for infra engineers
- Inability to scale the engineering department
Clearly, something needed to be done.
Rippling Service Catalog to the rescue
I set out to solve this challenge in March of 2023, and it resulted in the development of what’s now called the Rippling Service Catalog.
At Rippling, we typically try not to come up with custom tooling if something is already available on the market, and there are vendor-provided solutions for code ownership and service catalogs—like Datadog’s service catalog or Backstage. These are great tools, but as mentioned earlier, there are many interpretations of code ownership. For our interpretation, we needed a solution based on tracking files, which stored metadata about different escalation options (Slack, email, Opsgenie, etc.) and was easily programmable to act upon said metadata.
After consulting with peers at other larger startups, it became clear that many folks made their own tooling due to the customizations needed for this use case. With this in mind, I set out to create something small that was focused on the current need but also expandable for future use cases.
Here’s how it works: At the root of the git repository (most of our development is in a monorepo), we create this service_catalog.yaml file. In it, we keep a list of structured objects called “services.” In our implementation, a service is an entity responsible for code ownership, as we defined in the previous sections. A service looks similar to an engineering team, but we found that often, the same team would like different escalation/ownership details for different pieces of the code they work on or to share ownership of a piece of code with members from a different team. The concept of a service independent from the org chart could handle these cases.
Within our service, we put the different fields needed to define code ownership, as well as a list of file path prefixes to which this service claimed ownership (the more specific paths got supremacy over less specific paths). Specifically, the fields to define code ownership were the handles/ids needed to link to our monitoring/alerting tools. This list is very organic and tailored to Rippling's systems, but most of the tools should be familiar. We found a few key ideas that made the adoption and migration of this system easier:
- Include the programmatic IDs instead of display names as the source of truth, like the Slack channel ID instead of the Slack channel name. This allows Slack channels to be renamed without breaking the linkage.
- Make any schema changes in a backward-compatible way. For example, we used to have a Pagerduty team ID when we used Pagerduty for our alerts, but when we switched over to Opsgenie, we first added the Opsgenie field, made sure all services added their entries, and only then removed the Pagerduty field.
Here is a sample of one of our services:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
services:
- name: "billing"
github_team: "Rippling/billing"
jira_project_key: "BILL"
team_slack_channel_id: "REDACTED"
oncall_slack_handle: "billing-oncall"
email: "REDACTED@rippling.com"
opsgenie_team_name: "Billing"
datadog_handle: "opsgenie-billing-errors"
file_paths:
- "app/billing/"
- "app/billing_lib/"
- "app/billing_api/"
- "app/app_restriction_framework/"
- "app/unified_churn/"
- "app/bsc_permission/"The second part of the service catalog is a (surprisingly small) Python package whose purpose is to parse this file and do simple operations with it. For example:
- Given a file name, tell us what service owns it.
- Given a service, tell us what files it owns.
- Write the GitHub CODEOWNERS file to reflect this ownership.
We also added a CLI wrapper for human and bash (CI) usage, but that’s pretty much it.
Adoption
Once we wrote the service catalog tool, the real work of implementing company adoption began. Writing the code was actually quite simple. Most of this project's effort was in cross-team communication and coordination. At the start of this project, there was no formalized on-call or notification structure for all teams. Some teams had dedicated Slack channels, emails, or on-call rotations, while others didn’t. The service catalog project—and the push for its full adoption—gave the organization the impetus to make these standardization changes.
What followed was an engineering-wide, four-week migration initiative. This was a careful “internal public relations” project with official channels of communication, regular announcements and notifications, and buy-in from upper management to push teams to prioritize the migration. Along the way, we learned a few things:
- Do a pilot/beta with a few folks first: This step is really useful for ironing out the wrinkles before presenting the plan to hundreds of people.
- Over-communicate the goals: People cooperate far more when they know what is happening and why.
- Focus on small batches at a time: A small team can’t offer dedicated support to hundreds of engineers for a somewhat complex adoption/migration. Focus on a few teams at a time, and you will steadily and reliably reach everyone over time.
- Adapt based on feedback: Based on user feedback, we actually tweaked the service catalog to allow overrides for GitHub team reviewers for certain file paths.
With a few cycles of close communication with the product teams, our main repository got full ownership within a month.
Results

At the time of writing, it’s been a little over nine months since the adoption was completed. And this project has been a game changer.
Within a few months, we were able to take the infrastructure engineer entirely out of the equation and rely on automated alerting based on the service catalog. Rippling’s infrastructure engineers no longer need to fret about finding the correct engineer to ping upon failure, and they’re able to identify the on-call rotation to handle issues within 30 seconds. Infrastructure engineering burnout has disappeared, and the majority of the team’s efforts are now devoted to improvement and creating new features instead of maintenance.
Adopting the service catalog companywide encouraged much-needed reforms. The responsibility for code failure fixes was taken out of the infrastructure engineers’ hands and given to the official code owners. With the product teams directly on-call for their code, they began to prioritize reliability more, both in their code and with cross-timezone rotations. Also, if a team is wrongly assigned ownership to a piece of code, they’re incentivized to find the right owner. In a way, the longer we have the service catalog, the more accurate it gets.
The service catalog even greatly impacted the engineering roadmaps as it enabled us to track key metrics per team. For example, we can track test runtime or test flakiness per team and work with these teams to make adjustments (this will be the subject of my next blog post 🙂). We also use it to gamify the adoption of best practices, like linting, by creating team leaderboards. By giving us the ability to measure performance on a per-service/team level, the service catalog allowed us to roll out new institutional changes that were previously impossible.
We’re still finding more uses for the Rippling Service Catalog every day. After work was done in the production environment for Sentry alerts, the service catalog now serves as the backbone of Rippling’s alerting system. The security team uses the service catalog to track down owners for vulnerabilities in the code. And more work is being planned to expand Rippling’s concept of ownership beyond just files to include cloud resources, worker pools, and support multi-repo, too.
Conclusion
It can be difficult to see the importance of code ownership without witnessing the before and after, especially without a long-term roadmap of how it can be applied. Our team was definitely missing that when the project began, and it’s something we’ve identified and actively improved on. We know this is a common growing pain that infrastructure engineering teams face when scaling up.
Another key point of reflection from this project is how much developer relations play a part in infrastructure engineering. When starting the project, not much thought had been put into making adoption easy for product teams, and it took a lot of effort to make the adoption process smooth. It can be easy to forget that, as the infrastructure department, our customers are our colleagues, and we must make sure our changes are as seamless as possible for them. Fostering these relationships is just as much a part of the job as coding.
If this kind of work excites you, we’re hiring talented and passionate engineers at Rippling. Come join us!






